

blenderは独自のCPython runtimeを内部に持っていて、すべての操作をpythonで行うことができます。generativeにものを作ったり、特に大量のオブジェクトを操作する必要があるときなどに効果を発揮する素晴らしい機能です。
そしてPythonと言えばもはやAnacondaです。ほとんどの有用なモジュールがパッケージされているのでこれをblender-pythonでも使いたいというのは必然でしょう。
あわせて読みたい:

実は、blender-pythonと同じバージョンのPython(CPython)をOSにインストールして、そのモジュールをblender-pythonのsite-packagesにシンボリックリンクすれば、blender-python内からもほぼ問題なくanaconda経由のmoduleを使うことができます。
今回はその方法を解説します。blender 2.78以前ではnumpy以外のモジュールをシンボリックリンクすれば良かったのですが、2.79ではそれに加えてrequestsモジュールもbuilt-inのものが提供されているので上書きしないように注意する必要があります。
Contents
0. 下準備
blender pythonのバージョンは下図のようにpython consoleを開くと書いてあります。
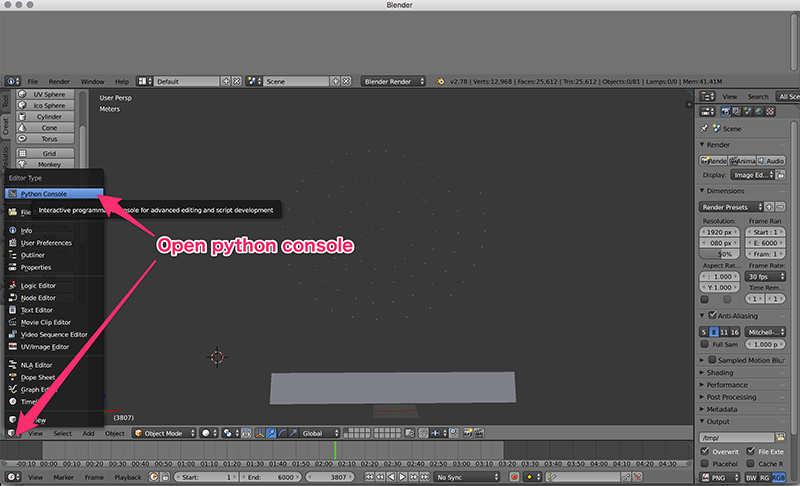
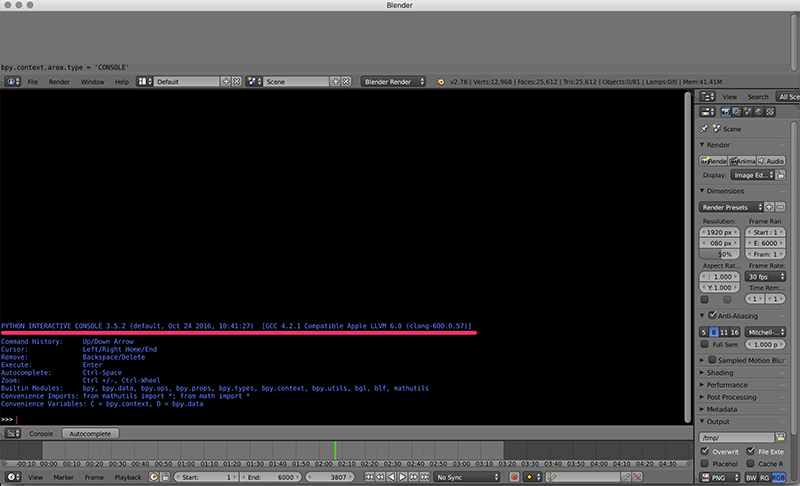
blender 2.78ではblender-pythonのバージョンは 3.5.2、blender 2.79では 3.5.3でした。
今まで使用してきて特に問題に出会ってないことから、今回はAnacondaのPython 3.6を使用した環境設定を説明しますが、もしマイナーバージョンも合わせて構築したいのであれば、記事の最後のAppendixを読んでください。
1. Anacondaのインストール
Anacondaの公式サイトから、OSに合った3.6バージョンのAnacondaをダウンロードしてください:
下記のようにインストール時のオプションを設定していると、後の手順でパスが違うとかにならずに楽です:
- インストール先のフォルダはデフォルトを使用
- “すべてのユーザー”にインストール
- “Add Anaconda to system PATH environment variable.” にチェックを入れる
- “Register Anaconda as the system Python 3.6.”にチェックを入れる
2. 必要なモジュールをインストール
PyPI等で必要なモジュールをインストールしておきましょう。
3. モジュールをリンクする
blender-pythonのライブラリ読み取り先に対して、anaconda内のモジュールからリンクを貼ります。windowsの場合は、下記のバッチファイルを適当な名前(*.bat)で保存して、管理者権限で実行します。macやlinuxでも同じようにシンボリックリンク(ln -s)すればOKです。
rem make links of anaconda3's modules to python 2.79's python
set source=C:\ProgramData\Anaconda3\Lib\site-packages
set target=C:\Program Files\Blender Foundation\Blender\2.79\python\lib\site-packages
set exclude1=numpy
set exclude2=requests
@echo off
for /F %%f in ('dir /b %source%') do (
if not %%f==%exclude1% if not %%f==%exclude2% (
if exist %source%\%%f\NUL (
mklink /d "%target%\%%f" "%source%\%%f"
) else (
mklink "%target%\%%f" "%source%\%%f"
)
)
)
@echo on
これでセットアップは終了です。blenderのPython consolesでpandasやsklearnがimportできるか確かめましょう。
新たなモジュールを追加したくなった場合は、anacondaのpip等でモジュールを追加して、再度新しいモジュールのリンクを追加すればOKです。上記バッチファイルの場合は再実行すれば完了です。
Appendix1: blender-pythonがクラッシュする操作
なぜなのか僕はよくわかってないですが、今回の記事のようにAnacondaのモジュールをblender-pythonから使った場合、matplotlibでプロットをshowしたりsaveするとクラッシュします。
なので図をプロットしたい場合はデータをファイルに書き出してからsubprocess.runなりを使って、描画部分だけシステムのpythonを使いましょう。
Appendix2: マイナーバージョンを合わせる場合
もしシステムのPythonとblender-pythonのマイナーバージョンも合わせたければ、Anacondaのvenv機能で環境を作りましょう:
conda.exe create -n py35con python=3.5 anaconda
この場合、pythonモジュールのインストール場所が
“C:\ProgramData\Anaconda3\Lib\site-packages”
から
“C:\ProgramData\Anaconda3\envs\py35con\lib\python3.5\site-packages”
に変わるので注意してください。
コメント